This entire post is a high-level summary of the motivations and contributions of my paper which was recently accepted to AISTATS 2020: Optimization Methods for Interpretable Differentiable Decision Trees in Reinforcement Learning.
Why aren’t normal neural networks interpretable?
Ultimately, neural networks are lots of matrix multiplication and non-linear functions in series. And following where a single number goes and how it affects the outcome of a set of matrix multiplication problems can be rather daunting.
Consider the cart pole problem from the OpenAI Gym. The objective of the challenge is to balance an inverted pendulum (the pole) on a cart that can shift left or right on a line. By just nudging gently left and right, it’s possible to keep the pole balanced upright. We can train agents to solve this problem without much issue, but if you wanted to visualize a network’s decision-making process, it wouldn’t be so easy. Then again, cart pole is a simple problem: There are only four variables in the state, and a network with two layers can solve the problem.
Perhaps the closest you could get is to draw out all of the different matrix multiplication operations that would need to take place, and then try to trace through the math each time. With such a simple problem and network, what might that look like?


As it turns out, it’s very complicated. To know what the network would do in any given state, we need to be able to run through 4 matrix multiplication problems, save the results, run through 2 more matrix multiplication problems, and then compare the two results you get. Even if we remove non-linear activations from the input-layer’s output, this is clearly not what we would conventionally call “interpretable.”
So what about differentiable decision trees?
Decision trees are a more classic machine learning approach which yield interpretability, simplicity, and ease of understanding. The actual format of a decision tree is essentially a list of “Yes or No” questions until the machine finally arrives at an answer.
Going back to cart-pole up above, we might say “If you’re to the left of center, move right. Otherwise, move left.” If we know that:
-
“A” is the cart position,
-
0 is center, and
-
negative is left,
then this is a very simple decision tree which could be drawn like so:

Now, this is a bit simplistic and in reality it wouldn’t actually do very well. There is a trade-off here between simplicity and performance. The complicated matrix math does quite well, but we can’t understand it. The dead-simple decision tree is very easy to understand, but it doesn’t do all that well. Can we combine the two?
As it turns out, yes! By structuring a network like a decision tree, we can learn how to perform well in a reinforcement learning environment, and then have all of the network’s “knowledge” captured in a convenient decision-tree shape. That doesn’t quite solve our matrix math problem, but it gets us closer.
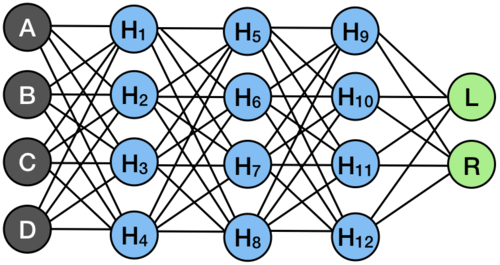
Instead of a multi-layer network with obscure mappings and math, we have simpler single-layer checks which spit out a “True” or “False,” and eventually a very small pair of weights on different actions. Each check is itself a layer of the network, and the outputs are themselves sets of parameters. So instead of a multi-layer network like this:
We can sort of decompose our network into mini sub-networks, where each mini-network is a single decision in the tree.
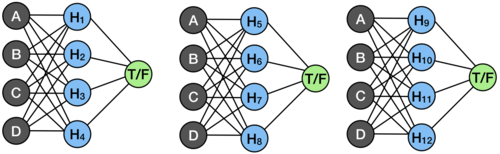
While this isn’t much simpler, we got rid of a nasty set of repeating hidden layers which would have been a pain to follow, but we still don’t want to figure out how each of these works in order to understand the entire system. So next up, we return to that idea of attention and simplifying layers of the network.
While training, the network is allowed to make use of all of its hidden units and learn the best solution possible. However, when it finishes training, we take advantage of attention to choose just a single variable to care about (or taking the feature with the highest associated weight value, as we do in our work). Not one hidden unit, just one input variable (like the cart position, A, for example). When the layer is only looking at one variable, we can actually just collapse all of the math into a single operation, multiplying by one weight and adding one bias. So taking one of the mini sub-networks above, we convert it like so:
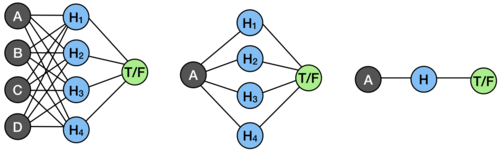
Now, we simplify even further and just convert the single operation into a simple check against the variable we care about (in this case, A). Then, we’ve successfully converted a mini sub-network into a piece of a decision tree!
When we repeat the process, we can convert any of our differentiable decision trees into ordinary decision trees. They can learn complicated and obscure ways to solve problems, but we can always convert them back into interpretable and clean decision trees to see how they work. To show an example, here is one that was able to nearly perfectly solve the cart-pole problem:

Compared to the matrix-multiplication headache of following a very simple neural network, this is cleaner and far more useful! We may still not have a great immediate understanding of what a pole angle > -0.41 really means, but this is much easier to interpret than the original neural network.
Why not just use a normal decision tree, but bigger?
There are other ways to get a decision tree for most machine learning problems! We don’t need to go through this complicated process of training a neural network and then extracting a decision tree, we can just directly learn one from the data. If we have somebody demonstrate how to balance a cart on a pole, we can use that data to learn a tree without needing a neural network. Using a trained neural network to provide 15 “perfect” demonstrations and then learned a decision tree directly from those demonstrations, and here is the tree that came out:
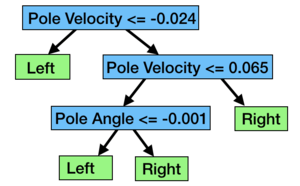
In reality, the tree that was returned was much larger, but so many of the branches or paths ended up being redundant (as in, a check leads to leaves that are all “Left”, so there was no reason to make the check in the first place) that it reduces down to this after some manual simplification. And as you might expect, unfortunately, it’s very bad at solving cart pole. The tree above averaged a score of somewhere near 60, where the decision tree extracted from a neural network averages 499, and the neural network model averages 500, the top score. So in short: we don’t use decision trees directly because they’re very bad.
Is this actually any more interpretable than the MLP?
To test whether or not these differentiable decision trees are truly more interpretable and usable by humans, we performed a user-study with 15 participants. In our study, participants were given an MLP as above (but with binary weights, to simplify the math), a decision tree from our approach (as above), or a decision rule list, which is a variant of a decision tree. Participants needed to predict the output of the network based on random inputs provided to them. We measured participant’s ratings of interpretability on a Likert scale as well as the time it took them to complete the task with each network.

The results of our user study confirm our suspicions: the tree and the rule-list are significantly more interpretable than the MLP. On average, they take far less time to trace out the policy, and our participants consistently rated the tree and the list as easier to use, easier to follow and understand, and clearer.
How do we actually learn differentiable decision tree parameters?
Assuming we want to deploy a DDT to reinforcement learning, we need to somehow learn the optimal parameters. Here we have a choice: policy gradient approaches, or Q-learning approaches? Both have shown promise across the field, and so we run a comparison on the effects of using them with DDTs. Our problem setup is simple:
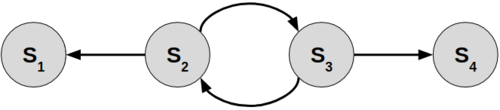
We consider a standard Markov Decision Process (MDP) with 4 states. Each run, agent starts in either S2 or S3, and gathers positive reward while it stays in one of those two states. However, the episode ends if the agent reaches S1 or S4. From this, it follows pretty clearly that the agent should always move right from S2, and move left from S3. If we were to put together a decision tree for this problem, we could do it pretty simply with just one node.
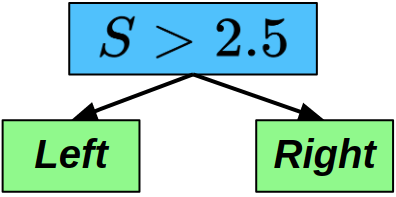
The optimal tree for this 4-state MDP is given in the image here. If the state is greater than 2.5 (meaning we’re somewhere on the right side of the chain), we should move left. If that isn’t true, and the state is less than 2.5 (we’re somewhere on the left side of the chain), then we should move right! This keeps the agent bouncing back and forth in the middle of the MDP, alive and accruing reward.
So we know what the solution should be for this MDP, what happens if we put together a simple 1-node DDT and drop it into this problem? We’ll assume that the tree is pretty well-structured already— True will evaluate to “Left”, False will evaluate to “Right”, and so we just want to know: which value should we be checking the state against? Put another way: what is the splitting criterion? The optimal setting is 2.5, so what will Q-Learning and Policy Gradient decide it should be?
Q-Learning
To figure out where Q-Learning might take our DDT, we plot out the parameter update for all of the different possible splitting criteria between 0 and 5. What we want to see is that the gradients of these updates are only zero in one place— 2.5. These zero-gradient points are called critical points, and they’re places where the model would stop updating its parameters (meaning it would consider itself finished training). Everywhere else, there should be some gradient, however small, nudging the parameters towards these critical points.
So what does that turn out to look like for Q-Learning?
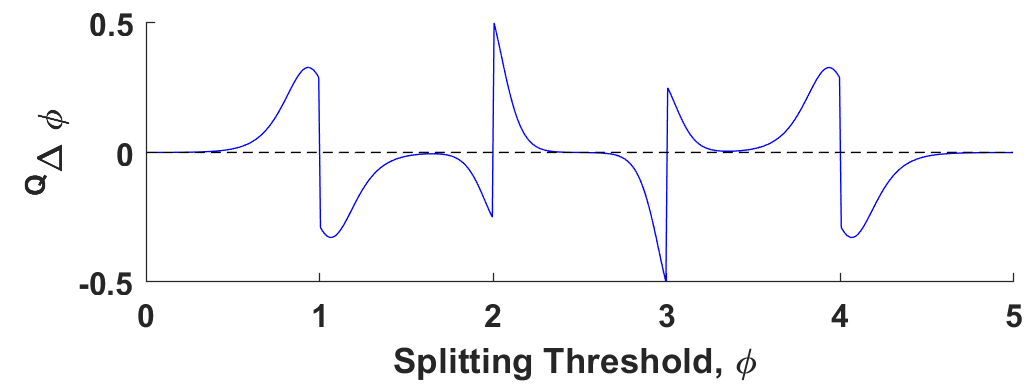
It turns out that Q-Learning presents us with 5 critical points, only one of which is coincident with 2.5. The other 4 are all sub-optimal local minima— places that the model would stop updating but which clearly do not present us with an optimal solution.
Policy Gradient
With Q-Learning examined, what about Policy Gradient approaches? We set the problem up the same way: plot gradient updates for all values of S between 0 and 5 and look for critical points— points that have zero-gradient.

Policy Gradient is so much more stable! For this problem, there is only one critical point, which is nearly exactly coincident with 2.5, the optimal setting.
The Takeaway
The takeaway from all of this is: if you’re going to work with DDTs in reinforcement learning, you should be training your agents with policy-gradient approaches rather than Q-Learning approaches. Policy gradient exhibits greater stability, more closely reflects the ground truth of the problem, and works well empirically! For the full details, have a look through the paper!
If you want pure performance: go for a neural network. It’s always going to be a stretch for any simple, linear algorithm or model to match the performance of a complex deep network. If you want interpretable decisions in your policy, try the differentiable decision tree. The differentiable decision tree offers both strong performance and very clear insight into the agent’s inner-workings, with plenty of room to explore new ways to both improve the expressivity of the network (through dynamic growth or more complex nodes) and room for future research on new approaches to interpretability within the tree and nodes (finding the most common paths, extracting more complex nodes, etc).
And if you decide to pursue differentiable decision trees in reinforcement learning, optimize with a derivative of policy gradient rather than Q-Learning! It will likely be more stable and less likely to fall into a bad local minimum.
For more details, check out the full paper, and feel free to reach out with questions to Andrew Silva. Special thanks to all co-authors involved with the project, and to our collaborators at MIT Lincoln Laboratory! And for more cool robotics and machine learning work, keep up with the CORE Robotics website!
Silva, Andrew, Matthew Gombolay, Taylor Killian, Ivan Jimenez, and Sung-Hyun Son. “Optimization methods for interpretable differentiable decision trees applied to reinforcement learning.” In International Conference on Artificial Intelligence and Statistics, pp. 1855-1865. 2020.
