Presenting your PhD Thesis Proposal is an exciting step in your PhD journey. At this point, you will have formed your PhD committee, developed initial results (potentially published one or more papers as the foundation to your proposal), and formulated a plan for conducting your proposed research. Many students can find the proposal experience stressful. In a sense, the proposal defines the “story” you will tell for years to come, including at your Thesis Defense, faculty job talks, and beyond. However, it is important to focus on the here and now rather than getting wrapped up in the expectations for the future and so many things that are outside of your control. Try to focus on what you can control and do the best you can to deliver a high-quality proposal.
This blog is a guide to help you do that — give a high-quality proposal presentation. This guide omits much about how to give a talk in general and instead focuses on common issues that come up specifically at the PhD Proposal Presentation stage of one’s academic development. For many, this may be the first time you will be presenting to an audience of professors your prior work and a proposal for what you will accomplish in a longform (e.g., 45-50 minutes) talk and be expected to defend your plan for an additional 45-50 minutes. Remember, the Committee’s job is to critique your work and challenge you into a better Thesis direction, to make your research better. Expect to be challenged and for your proposed work to change coming out of the proposal — this is a good thing 🙂
Having said all that, here is a non-exhaustive list of tips in three sections: Before, During, and After (i.e., the Q&A session) the proposal presentation.
Before The Proposal
1) Meet Committee Members a priori
Interviewing your Committee members before your Proposal is a great way to get to know them personally and allow you to assess the compatibility of the Committee Candidate and yourself. Share with them a compressed thesis pitch and get their feedback (include the proposed Thesis Statement from Point 2 below). If there appears to be an irreconcilable issue with your proposed work, you should both (1) consider the feedback you received with your PhD advisor to see if you can make the proposal better and (2) consider whether that committee member might present an insurmountable critic for you in successfully defending. Not everyone will like your work — that is ok. Just try to learn from every critic to see if you can make your proposal sharper.
After selecting your committee, meet with each member before the Proposal Presentation to ask if you are ready to Propose. That will give you a good indication (and hopefully lead to more profound feedback) of the level of critique of your work, as well as their expectations for improvements.
- It allows you to get comfortable with them, making the Proposal presentation less stressful.
- It gives you an opportunity to present the work to your Committee Members and give them an overview of what they can expect from the Proposal.
- If they support you going through with presenting your Proposal, they are more likely to support you during the Proposal and vote in your favor. If they state that your work is not ready to be proposed, they can also offer suggestions to improve it and ensure that you are ready to propose.
- It allows the student to get a sneak peek at questions the Committee Members may ask during the Proposal and gives you time to prepare answers.
During The Proposal
2) Have a clear Thesis Statement
- Present the thesis statement before going over your research and at the end, tying everything together with that “golden” paragraph.
- A Thesis Statement should be nonobvious. Always remember that the proposal should set up the proposed research, experiments, and analysis. These components will serve as the supporting arguments and evidence in favor of your Thesis Statement.
- Be mindful that your Thesis’ scope presented in your Proposal is subject to change based on feedback from the Committee. The purpose of clearly laying a Thesis Statement is to show that you are working towards a cohesive topic.

Figure 1: Sample Slide from Pradyumna Tambwekar’s Proposal. The student shows a clear statement early in the presentation, and breaks it down into the main steps, which will serve as his roadmap.
3) Have a Venn Diagram of the Literature Review
Every proposal needs to present to the committee a review of the relevant literature. The proposer needs to convey that the proposer has assimilated a representative set of knowledge from prior work and that the proposed work is novel and significant. A Venn Diagram of the research based on topics is a good method of presenting prior work and situating your proposed work within this sea of prior work. Typically, your Thesis will be at the intersection of multiple (sub-)fields, and your work would lie at the intersection. Here are some advantages of this diagram:
- Having a Venn Diagram of previous literature, and where your own previous and future works fall into shows that you have done your literature review, have worked on topics related to these research and how your work fits in the broad scope of the fields.
- It showcases the novelties that you are bringing to the research committee. Most theses combine multiple topics into a cohesive whole and address a problem that had not been addressed, or use an approach that has not been used in the past.
- It makes your committee have more confidence in your work given your understanding of relevant literature and how your scientific production fit in to the field.

Pro Tip: While a Venn Diagram is a good starting point, you can consider variations.
4) Reminders, scaffolds, and roadmaps
The flow of your presentation must be smooth, and this is a great technique to let the audience know how things are connected and whether you are done with a point, or still talking about it. Jumping from topic to topic would get your audience confused. Each work should be linked to the Thesis Statement and ideally to each other. Make sure you verbally and graphically tell the audience when you are switching from one topic to another, and how they relate (in case they do).
- Roadmap: Your Thesis should hold cohesion, a story that you can refer to as you progress through your presentation. A roadmap is an overview of the steps, aims, and previous research you have conducted that make up your work. These are the parts that make up your Thesis. The purpose of the roadmap is to allow for a smooth flow of your presentation and a method for your Committee to evaluate each work with respect to the whole.
- Scaffolding: Before presenting each research aim, refer back to the Thesis Statement and previous research you have done, point out what needs to be addressed next and how it relates to the next research aim you are going to present.
- Reminders: Once each section of your research is complete, refer back to your Thesis statement, explain how what you have presented fits into the broader scope of your Thesis, and re-emphasize your Thesis Statement.
Consider the example outline slide shown below (Figures 1-2) that combines a presentation overview and elements of a thesis statement that would appear throughout the presentation to transition between sections.

5) Acknowledge collaboration
It is likely that you have worked with others when doing research. Be clear on who has done what and assign credit where it is due as you go through each of your research aims, preventing possible accusations of plagiarism. Acknowledge second authorship (i.e. “in this study led by Jane Doe, we looked into…”). Collaboration is not a bad thing! You just need to acknowledge it up front.
6) The Art of Story Telling (Your Technical Deep-dive)
The best stories have one nadir or low-point. In a story like Cinderella, the low-point is typically sad, coinciding with the protagonist’s efforts having fallen apart. However, in the PhD thesis proposal, you can think of this point as the opportunity for the deepest technical dive in your talk. Typically, an audience has a hard time handling multiple deep-dives — humans can only pay attention hard enough to understand challenging, technical content about once in a talk. Proposals that start with the low-level technical details and stay low-level for the next hour are going to cause your audience to have their eyes glaze over.
Note: You can also think of the beginning of the story as either an exciting motivation (like Man In Hole or Boy Meets Girl) or a motivation based upon a tragic or scary problem that your research is trying to address (e.g., like Cinderella). This point deserves its own whole blog post! Stay tuned 🙂

7) Modulate your voice and body language
Just like the entire presentation tells a story, think of each slide as telling a story. Your voice and body language can do a lot to help the audience follow the argument you are trying to make.
- Use your steps around the room to help with your pacing (it is often helpful to sync your voice with your steps).
- Use dramatic pauses (and stop walking) after each argument or punchline – that helps the audience to absorb your point or catch up with the train of thought.
- Upspeak can be helpful to show enthusiasm in between points, but be mindful that its overuse could be perceived as a lack of confidence.
- Breathe from your diaphragm.
- Other voice dynamics techniques can be useful.
8) Talk about everything on your slide
If you have content on your slide, your audience will want to understand it. If you do not explain it, that will frustrate your audience. Please take the time to talk through everything on your slide. If you don’t want to talk about it, then perhaps you shouldn’t have it on the slide to begin with!
If you have a lot of content on a slide, use animations to control when piece of text or figures pop up on your slides. Otherwise, your committee may start paying attention to the slide to understand the myriad of content and ultimately ignore everything you are saying. Animations are your friend for complex slides. Use animations (or sequences of “build-up” slides) to get the timing right so that your voice and the slide visuals are synergistic. Though, please note that animations can become cheeky, so don’t go overboard.
A key issue here is that proposer often forgets to explain all figures and plot axes. Your committee will not instantly understand a figure even though it is a visual. Describe the metrics used, go through the legend, and detail every aspect of the plot so that each member of the audience can see the patterns you want them to recognize.
In summary, you need to:
- Convey clarity and transparency.
- Define and explain the axes and metrics.
- Make it clear whether higher or lower is better for each figure.
- Note: explaining a figure helps with controlling your own pacing and locking the attention of the audience. Use that moment to re-calibrate it.
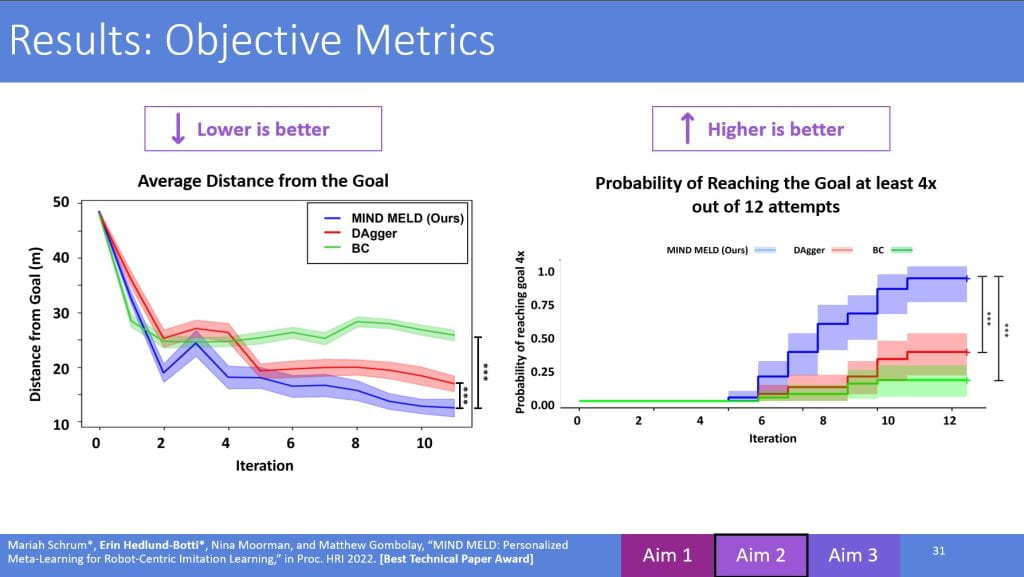
9) Have takeaways or “bumpers” on your slides
Clearly show what the scientific novelties/engineering advances of your work are and why it is worth doing what you are doing. This is the part where salesmanship comes in. Answer the following questions:
- What is the Scientific Impact/Advancement?
- Where does it stand with respect to prior literature and how is it novel?

10) Have a Timeline and a List of Planned Publications
A Proposal is a plan for the future that your Committee can look into and suggest changes going forward to the final stretch of the Thesis. As such, a timeline in the form of a Gantt Chart, along with a list of Planned Publications would provide a greater insight on what the Proposed work will be and how it will be done.
The planned work acts as a preview of what the Committee can expect from the Thesis Defense and when it will take place. It also allows them to assess both the quality and feasibility of the proposed work.
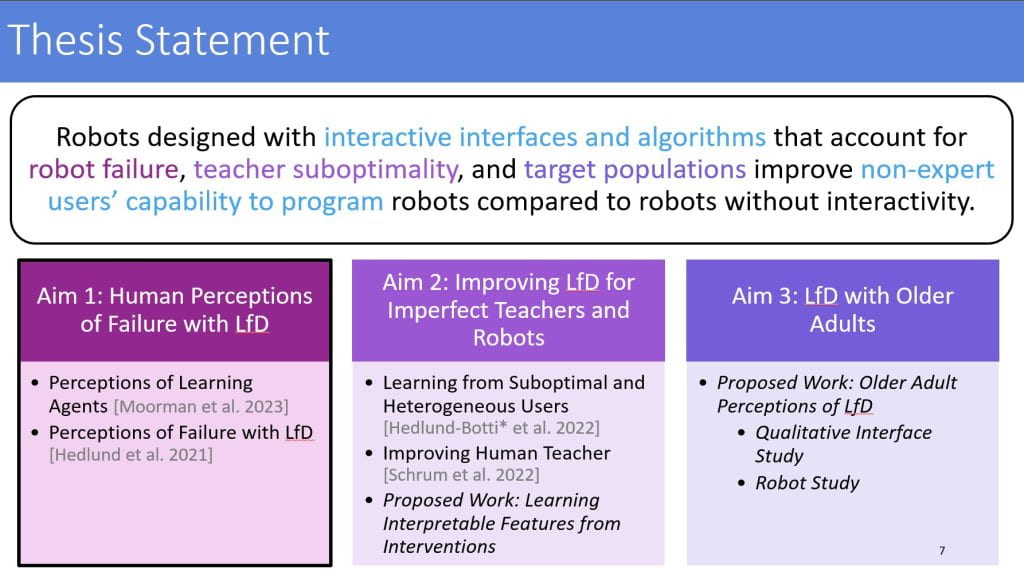
After The Proposal Presentation (The Q&A Session)
11) First things first…
- Repeat the question back for the sake of the audience.
- It allows the audience to pay attention to the question being answered if they have not heard it at first.
- It gives you time to think over an answer.
- It allows you to get a confirmation that you understood the question. It also allows them a chance to interrupt and clarify the question.
- If there is jargon in the question asked…
- If you are unfamiliar with a jargon, ask them to explain it, especially if it is within their specific area of expertise.
- If you do know what the jargon means (or if it has multiple definitions and one is best for your purposes), define it from your perspective (ideally backed up by literature that you can reference).
- Discuss the scope of your research with respect to the field in question. How does it fit in with other research? What specifically is being tested and what is not being tested, and for what reason.
- Thank a question-asker for “good” questions (not “bad” questions).
- First, note that “good” and “bad” are commonly used adjectives but are judgmental, unhelpful, and best to avoid. A better way of describing these types of questions would be to differentiate between 1) questions for which there is not an established answer and would require an expert to deeply think about the answer and possibly conduct experiments or analysis versus 2) questions with a well-established answer. It is best never to say a question is actually good or bad.
- With that established, a common practice is for an answerer (e.g., the PhD Thesis Proposer) to say, “That’s a good question,” before answering each question. The challenge here is that experts in the field hearing the proposer label a question as “good” when the question has a well-established answer can make the proposer appear either ignorant or patronizing.
12) When someone asks you a question and you don’t know the answer…
In the case you get asked a question to which you do not know the answer, say that you do not know the answer. A part of being a scientist is to admit one’s ignorance and work to address it. Not everyone is aware of everything. Acknowledging a lack of familiarity with a topic or a research is acceptable and shows a scientific mindset.
- When relevant, use phrases such as:
- “I am unfamiliar with that work, but I will be glad to look into it after the proposal.”
- “I am not sure, but I would hypothesize/speculate that the outcome would be…”
- “I have not heard that term before. Could you please define it for me?”
- “I do not have an answer to that, but here is how I would go about conducting an experiment to find out the answer: …”
- DO NOT pretend to know something you do not know. It is easy for an expert to tell your familiarity with a topic with the right questions.
- After proposing, look up the information the Committee presented. By following up any mistake or discussion point, you show your diligence and reassures the Committee that you are willing to compensate for your lack of knowledge.
- Follow up, either in a later meeting or through email, after doing the research related to the information you are unfamiliar with. Show that you are willing to learn and improve.
13) When the audience points out a reasonable weakness or limitation in your approach, acknowledge it.
If the person asking a question makes you realize you have a weakness in your proposal or position, admit the validity of their question or point. This may be a “proposal defense,” but don’t dig in your heels and defend a flawed position with weak arguments. Be respectful and humble.
Research is never perfect. Being aware of where and when your research fails is an important part of being ready to be a PhD Candidate. The Committee wants to see the limitations/weaknesses of your work. They also want to see that you are aware of these limitations and either work to address them, or have an idea of how it can be addressed in future works.
14) Have Backup Slides
Show off your preparation and have backup slides. Prepare for questions that you would expect (e.g., regarding more technical details, ablation studies, metrics’ definitions, why you have chosen this approach compared to any other alternatives).
When a question comes up, do not try to answer the question just with your own voice. Take advantage of the preparation you have done and go to backup slide you prepared. The more you can show you were prepared, the more likely the committee will be to give you the benefit of the doubt and cease their interrogation.
Be careful, though. Often students will copy+paste equations or simply “dump” material from external sources into backup slides. When the proposer then pulls up this content and seeks to present it, the proposer will fall short of coherently explaining the content on the slide. You are responsible for everything you put on every one of your slides, so please do your due diligence to understand the material you are presenting.
Pro tip: Don’t copy+paste any equations. Professors often look for this and see it as a sign you might not understand the content. Take the time to recreate the equations with your own symbology using an equation editor in the software you are using to create your slide deck.
15) When the Committee Asks About Applications, You Do Not Have to Invent Something New
Your research should address an important, existing problem — or at least one the committee thinks is likely to exist and be important in the near future. Your motivation slides should present that problem and show the committee that you have considered why the work you have done is important.
- When asked about applications, reference the applications you have already modeled or analyzed. You do not have to come up with new applications as you are presenting — moving further away from the application that you have worked on exposes you to questions that may be unfamiliar.
- If asked about a potential application that you have not thought through before, be open to think-aloud to consider how you might go about applying your work to that scenario. However, let the committee know first that you have not studied that potential application and are thinking aloud about how to assess both the feasibility and success of such an application in the future.
- Professors are looking to ground work done on toy or simulated domains (e.g., a grid-world domain, a videogame, etc.) into something able to solve real-world problems. Researchers should be aware of what they are trying to contribute towards.
- Ideally, work done in a simulated or toy domain has a real-world analogue. Without over-selling your work, ground your analysis in the real-world domain that motivates your work.
- Have a very pithy description of the domains you tested or are planning on testing. What are the scientific novelties/engineering advances of your work and why it is worth doing what you are doing. Keep it short and relatable, similar to an elevator pitch. Provide generic examples and do not over-complicate. If someone requires a more in-depth explanation, they can always ask.


