Bootcamps
- Gradient Descent
- Backpropagation
- Value Iteration and Q-Learning
- Policy Iteration and REINFORCE
- On v/s Off-Policy Learning
- Deadly Triad
- Variational Inference in Heterogeneous Apprenticeship Learning
- KKT Conditions
- Projected & Mirror Gradient Descent
Navigating the PhD
CORE Robotics Research
Scheduling Robots with Graph Attention Networks
Authors: Zheyuan Wang, Matthew Gombolay
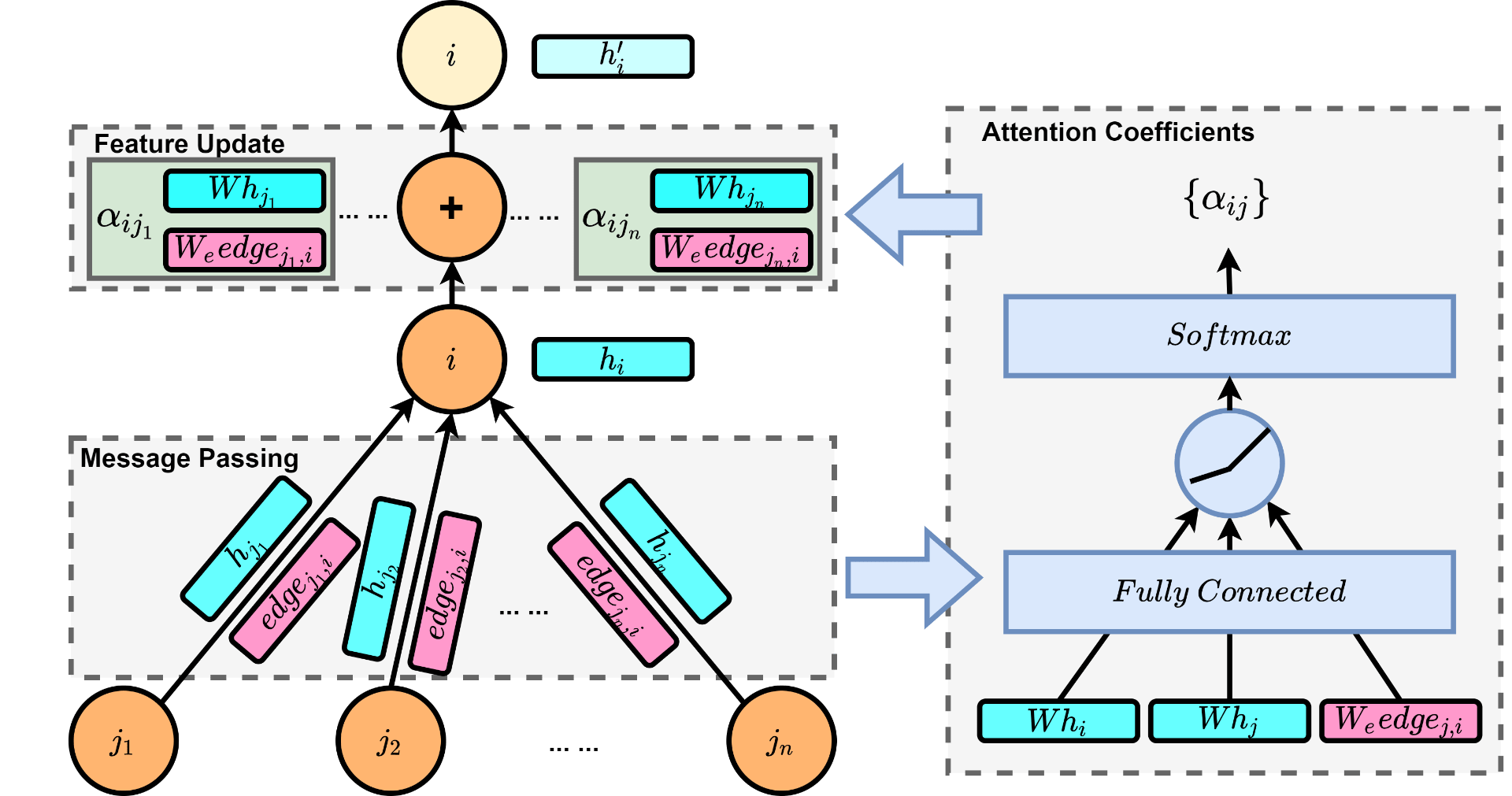
In recent years, deep neural networks have brought about breakthroughs in many domains, including image classification, nature language understanding and drug discovery, as neural nets can discover intricate structures in high-dimensional data without hand-crafted feature engineering. Can deep learning save us from the tedious work of designing application-specific scheduling solutions? It will be desirable to let the computer to autonomously learning scheduling policies without the need of domain experts. Promising progress has been made towards learning heuristics for combinatorial optimization problems. Yet previous research focuses on significantly easier problems than the multi-robot scheduling problem. To push this idea further, we try to develop a novel neural networks-based model that learns to reason through the complex constraints in multi-robot scheduling for constructing high-quality solutions. [read more]
Effects of Anthropomorphism and Accountability on Trust in Human-Robot Interaction
Authors: Manisha Natrajan, Matthew Gombolay

We conduct a mixed-design human subjects experiment to understand factors governing trust in the context of human-robot interaction. To the best of our knowledge, we are the first to perform an integrated study on trust involving multiple robot attributes at once. We consider factors such as perceived anthropomorphism (or how human-like the robot is perceived to be), embodied and virtual robots, and robots exhibiting different behaviors while providing assistance to users in the context of a time-constrained game.
Further, we investigate how to mitigate errors due to over-compliance or under-reliance in human-robot interaction. We also include a coalition-building preface, where the agent provides context as to why it might make errors to evaluate the change in trust. [read more]
Joint Goal and Strategy Inference across Heterogenous Demonstrators via Reward Network Distillation
Authors: Letian Chen, Rohan Paleja, Muyleng Ghuy, Matthew Gombolay
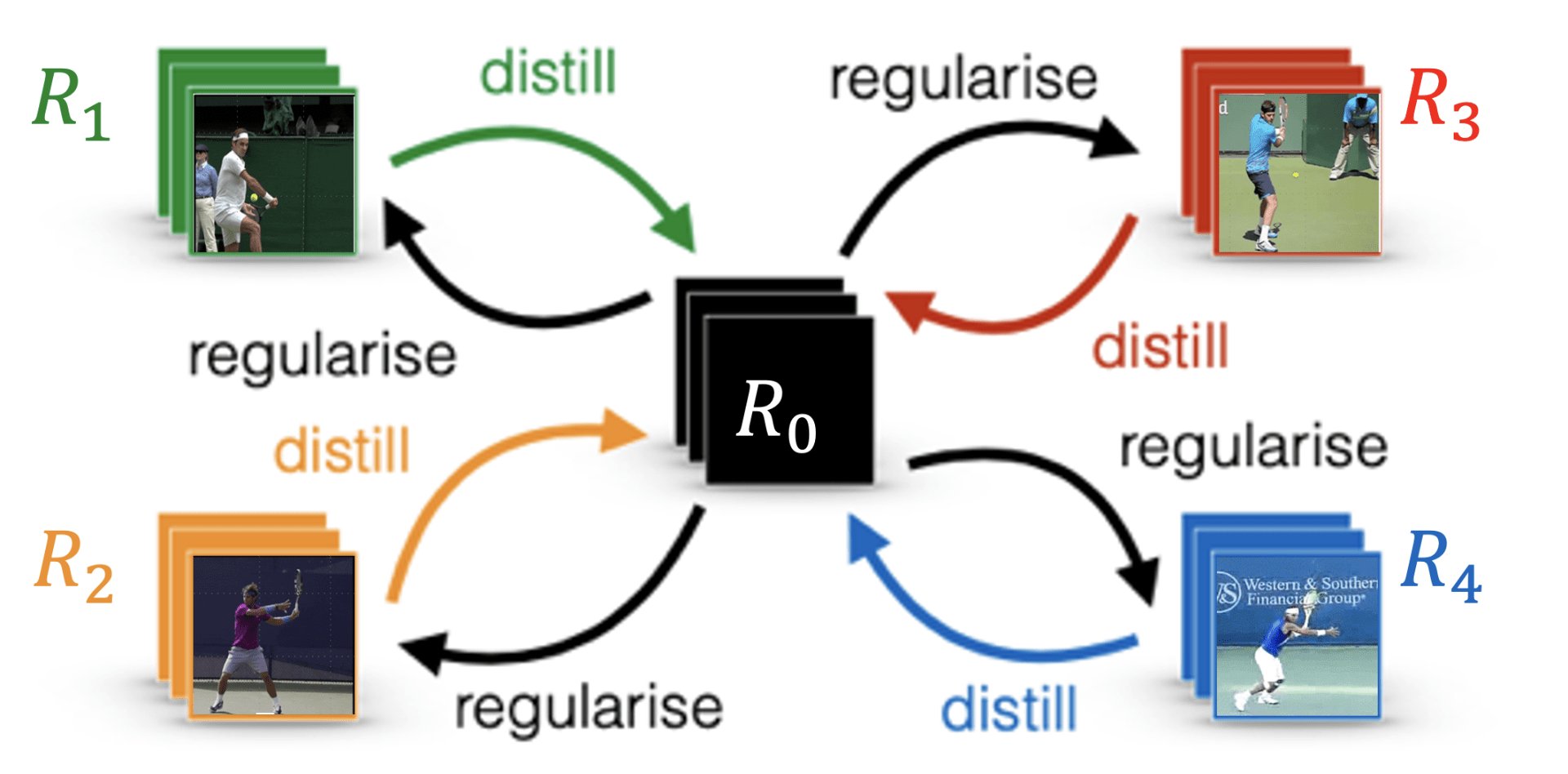
“Learning from Demonstration” (LfD) techniques aim to enable robots to be taught by non-roboticists how to perform tasks, such as folding laundry, driving a car, or performing surgery. For decades, people have relied on the incorrect assumption that every teacher performs tasks similarly, i.e. everyone folds laundry or performs surgery in a similar fashion. However, this assumption is often not true. We take a new perspective in LfD by modeling every human teacher as having a shared notion of the desired task (a common goal) along with a teacher-specific notion (e.g., strategy, or style) for performing the task. Accordingly, we present a novel method, Multi-Strategy Reward Distillation (MSRD), a novel Inverse Reinforcement Learning (IRL) technique that automatically finds and takes advantage of the common goal shared by all teachers (e.g., perform the task well) while teasing out and accounting for what makes each teacher unique! [read more]
